第 2 章 数据的表示和运算
内容
- 数制和编码
- 进位计数制及其相互转化;定点数的编码表示
- 运算方法和运算电路
- 基本运算部件:加法器,算术逻辑单元 ALU
- 加减运算:补码加减运算器,标志位的生成
- 乘除运算:乘除法运算的基本原理,乘法运算和除法电路的基本结构
- 整数的表示和运算
- 无符号整数的表示和运算;带符号整数……
- 浮点数的表示和运算
- 浮点数的表示: IEEE 754 标准;浮点数的加减法运算
2.1. 数制与编码
2.1.1. 进位计数制及其相互转换
计算机内部使用二进制来编码
- 二进制只有两种状态,使用有两个稳定状态的物理器件就可表示每一位。
- 二进制位 1 和 0 恰好对应“真”和“假”,为逻辑运算和程序中的逻辑判断提供便利条件。
- 编码和运算规则简单,通过逻辑门电路能方便实现算术运算
一个 进制数 可表示为
这部分导论讲得太清楚了,已经刻入 DNA 了,不写了
一些例子
2.1.2. * BCD 码
四位一组,用四位表示一位十进制数
2.1.3. 定点数的编码表示
根据小数点的位置是否固定,在计算机中有两种数据格式:定点表示和浮点表示。常用定点补码整数表示整数,用定点原码小数表示浮点数的尾数部分,用移码表示浮点数的阶码部分。
1. 机器数的定点表示
- 定点整数:是纯整数,约定小数点位置在有效数值部分最低位之后。最高位为符号位,其余为数据位
- 定点小数:是纯小数,约定小数点在符号位之后、有效数值部分最高位置之前。若数据 , 是符号位, 是最高有效位, 为数值的有效部分。
2. 原码、补码、反码、移码
1. 原码表示
纯小数
,字长为 8 位,则原码为 ,,其中最高位为符号位
纯整数的原码
,字长为 8 位,原码为 ,,其中最高位为符号位
原码整数的表示范围关于原点对称,若字长为 ,表示范围为 。
源码有正零和负零
2. 补码表示
纯小数
若 ,字长为 8 位,其补码表示 ,
若字长为 ,则补码表示的范围是
纯整数
正数与原码一致,负数与自身的绝对值相加得到
若字长为 ,表示范围为 ,零是唯一的。
4. 移码表示浮点数的阶码
只能表示整数
移码就是在真值 上加上一个常数(偏置值),通常取 ,相当于在数轴上正向便宜若干单位。
,其中机器字长为
移码中零表示唯一,。移码保持了数据原有的大小顺序。
2.1.4. 整数的表示
1. 无符号整数
一个编码的二进制位全部用来表示数值,范围是 ,字长为
2. 带符号整数
将符号数值化,将符号位放在有效数字的前面。通常用补码表示,若字长为 ,表示范围为
2.2. 运算方法和运算电路
2.2.1. 基本运算部件
运算器由 ALU 、移位器、状态寄存器、通用寄存器等组成。基本功能包括加减乘除四则运算,与或非异或等逻辑运算,以及移位、求补等操作。 ALU 的核心是加法器。
1. 一位全加器
和与进位的表达式:
2. 串行进位加法器
把 个全加器相连可以得到 位加法器,称为串行进位加法器。每级进位直接依赖于前一级的进位,进位信号是逐级形成的。
进位运算较慢
3. 并行进位加法器
令 ,全加器的进位表达式
其中 或 时,
这种进位方式是快速的,与位数无关。但随着加法器位数增加, 的逻辑表达式会变得越来越长,使电路结构复杂。
4. 带标志加法器
无符号数加法器只能用于两个无符号数相加,不能进行带符号整数的加减运算。为了能进行带符号整数的加减运算,还需要在无符号数加法器的基础上增加相应的逻辑门电路,使得加法器不仅能计算和差,还能生成相应的标志信息。
- 溢出标志 OF
- 符号标志 SF 即为结果的最高位
- 零标志 ZF 只有当结果为全 0 才为“真”
- 进位/借位标志 CF
5. 算术逻辑单元 ALU
核心是带标志的加法器,同时也能执行与或非等逻辑运算。
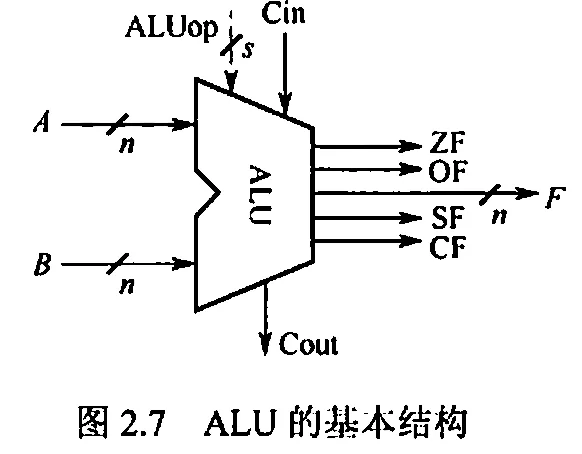
2.2.2. 定点数的移位运算
1. 算术移位
对于正数,由于原码、反码、补码相同,因此移位后的空位都用 0 来补。
对于负数,则有不同的规则。原码补 0,补码左移填 0 ,右移填 1 ,反码填 1 。
对于补码,在右移的时候,需要保证符号不变,因此负数右移,前面需要填 1 。
2. 逻辑移位
直接视为无符号数
3. 循环移位
移出的数位又被移入数据中,而是否带进位要看是否将进位标志加入循环中。
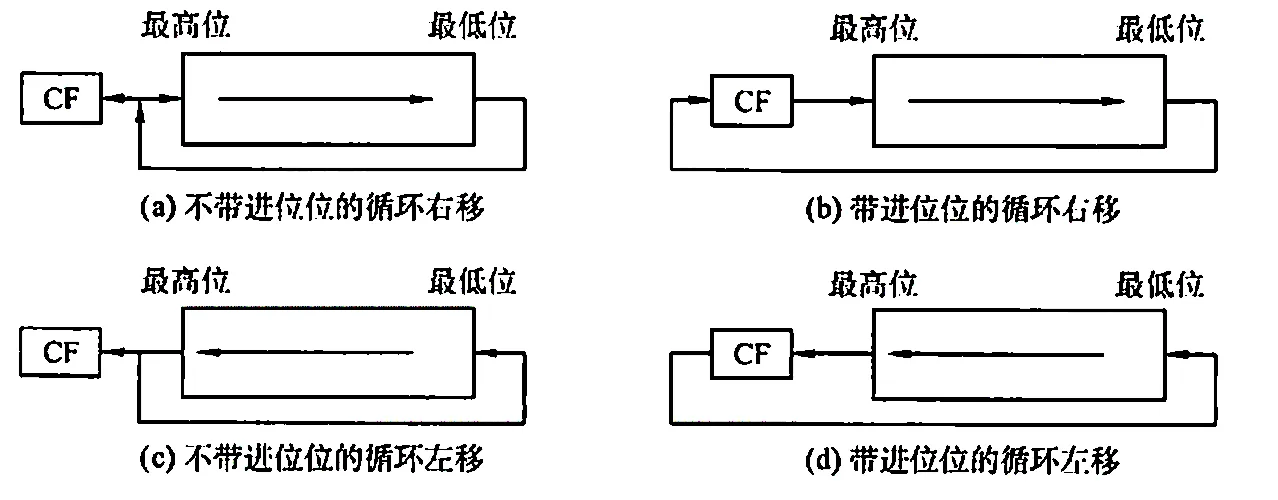
2.2.3. 定点数的加减运算
1. 补码的加减运算
2. 补码加减运算电路

- 对于无符号数, OF 无意义, SF 无意义
- 对于无符号数, CF 有实际意义
3. 溢出判别方法
- 正 + 正 = 负(正 - 负 = 负)
- 负 + 负 = 正(负 - 正 = 正)
其实书上讲得这些方法感觉都很难去实际想象,可能更多讲得都是用于机器实现吧。
2.2.4. 定点数的乘除运算
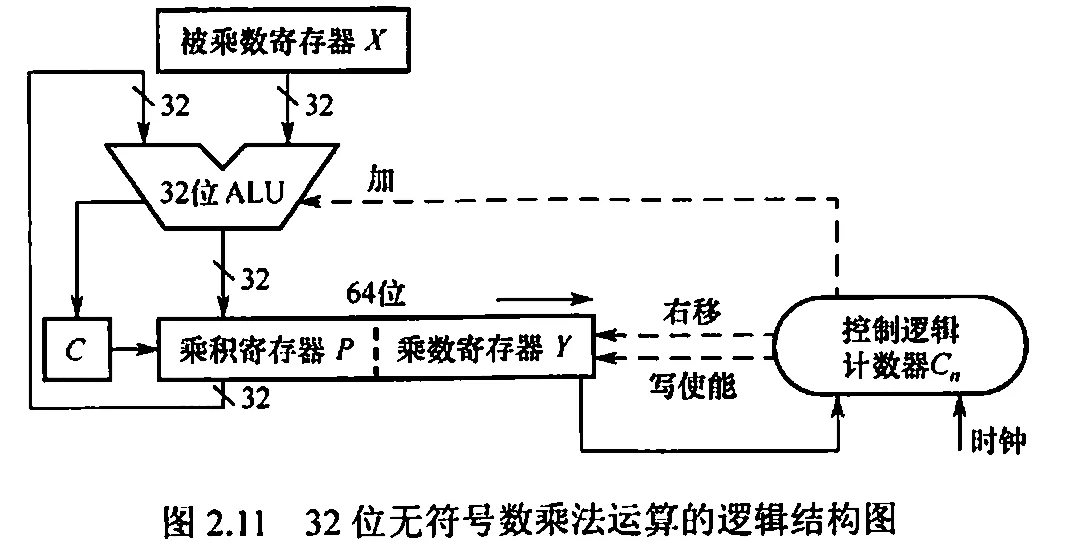
1.定点数的乘法运算
由累加和右移实现,可分为原码一位乘法和补码一位乘法
原码一位乘法
符号位与数值位是分开求的。
采用原码乘法求
0.0000 1011| start+|x| 0.1101 ^| y4=1, +|x|-------------- | 0.1101 |>> 0.0110 1101|1+|x| 0.1101 ^| y4=1, +|x|-------------- | 1.0011 |>> 0.1001 1110|11+ 0 ^| y4=0, + 0-------------- | 0.1001 |>> 0.0100 1111|011+|x| 0.1101 ^| y4=1, +|x|-------------- | 1.0001 |>> 0.1000 1111|1011符号位为负,得
2. 无符号乘法运算电路
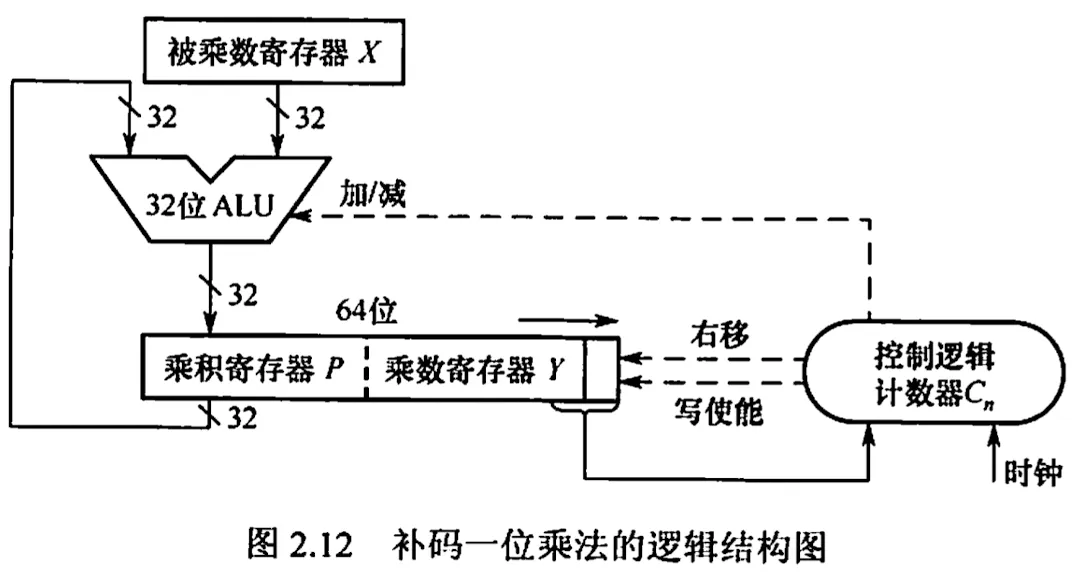
补码一位乘法( Booth 算法)
有符号数的乘法,采用相加和详见操作计算补码数据的乘积
,
- 符号位参与运算,运算的数均以补码表示
- 被乘数一般取双符号位参与运算,部分积取双符号位,初值为 0,乘数取单符号位
- 乘数末位增设附加位 ,初值为 0
- 根据 的取值来确定操作
- 移位按补码右移规则进行
- 按照上述算法进行 次操作,但第 步不移位,仅根据 的比较结果做相应计算。共进行 次累加, 次右移
| 高位 | 低位 | 操作 |
|---|---|---|
| 0 | 0 | 部分积右移一位 |
| 0 | 1 | 部分积加 ,右移一位 |
| 1 | 0 | 部分积加 ,右移一位 |
| 1 | 1 | 部分积右移一位 |
设 ,采用 Booth 算法计算
高位部分积 低位部分积/乘数 0.0000 0.1011|0_ y4y5=10, +[-x]+[-x] 0.1101 |-------------- | 0.1101 |>> 0.0110 10.101|10 y4y5=11, +0+0 |-------------- | 0.0110 |>> 0.0011 010.10|110 y4y5=01, +[x]+[x] 1.0011 |-------------- | 1.0110 |>> 1.1011 0010.1|0110 y4y5=10, +[-x]+[-x] 0.1101-------------- 0.1000>> 0.0100 00010.|10110 y4y5=01, +[x]+[x] 1.0011-------------- 1.0111结果为
补码乘法运算电路
2. 定点数的除法运算
可转换成“累加-左移”,分为原码除法和补码除法
符号扩展
在算术运算中,又是必须把带符号的定点数转换成具有不同位数的表示形式。例如,某个程序需要将一个 8 位整数与另外一个 32 位整数相加,想要的到结构,必须先将 8 位数扩展到 32 位数。
- 正数的扩展只需在前面加 0
- 负数的扩展根据机器数的不同而不同。原码表示负数与正数相同,只是符号位为 1 。补码表示的负数:原有形式的符号位移动到新形式的符号位上,新表示的所有附加位,对于整数用 1 填充,对于小数用 0 填充。
原码除法运算(不恢复余数法)
也称原码加减交替除法。特点是商符和商值是分开进行的,剑法操作用补码加法实现,商符由两个操作数的符号位异或形成。
设被除数 ,除数 ,则
- 商的符号
- 商的数值
计算 的运算规则:
- 先用被除数减去除数,当余数为正,则商上 1 ,余数和商左移一位,再减去除数;当余数为负,商上 0 ,余数和商左移一位,再加上除数。
- 当第 步余数为负时,需加上 得到第 步正确的余数(余数与被除数同号)
设 ,采用原码加减交替除法求
被除数 商 说明 0.1011 0.000|_+[-|y|] 1.0011-------------- 1.1110 0.000|0 部分余数为负,商上 0<< 1.1100 0.00|0_+[y] 0.1101-------------- 0.1001 0.00|01 部分余数为正,商上 1<< 1.0010 0.0|01_+[-|y|] 1.0011-------------- 0.0101 0.0|011 部分余数为正,商上 1<< 0.1010 0.|011_+[-|y|] 1.0011-------------- 1.1101 0.|0110 部分余数为负,商上 0<< 1.1010 |0.110_+[y] 0.1101-------------- 0.0111 |0.1101 部分余数为正,商上 1,,余数
补码除法运算(加减交替法)
补码除法的特点是符号位与数值一起参与运算,商符自然形成。除法第一步根据被除数和除数的符号决定是做加法还是减法;上商的原则根据余数和除数的符号位共同决定,同号上商 1 ,异号上商 0 ,最后一步恒商 1
规则如下
- 符号位参加运算,除数与被除数均用补码表示,商和余数也用补码表示
- 若被除数与除数同号,则被除数减去除数;如果异号,则被除数加上除数
- 若余数与除数同号,则商上 1 ,余数左移一位减去余数;若余数与除数异号,则商上 0 ,余数左移一位加上除数
- 重复上一步 次
- 若对商的精度没有特殊要求,一般采用“末位恒置 1” 法
设 ,采用补码加减交替法算
,
被除数 商 说明 0.1000 0.000|_+[y] 1.0101 [x]补 与 [y]补 异号,+[y]补-------------- 1.1101 0.000|1 部分余数与 [y]补 同号,上 1<< 1.1010 0.00|1_+[-y] 0.1011 +[-y]补-------------- 0.0101 0.00|10 部分余数与 [y]补 异号,上 0<< 0.1010 0.0|10_+[y] 1.0101 +[y]补-------------- 1.1111 0.0|101 部分余数与 [y]补 同号,上 1<< 1.1110 0.|101_+[-y] 0.1011 +[-y]补-------------- 0.1001 0.|1010 部分余数与 [y]补 异号,上 0<< 1.0010 |1.010_+[y] 1.0101 +[y]补-------------- 0.0111 |1.0101 末位恒置 1有 ,余数
除法运算电路
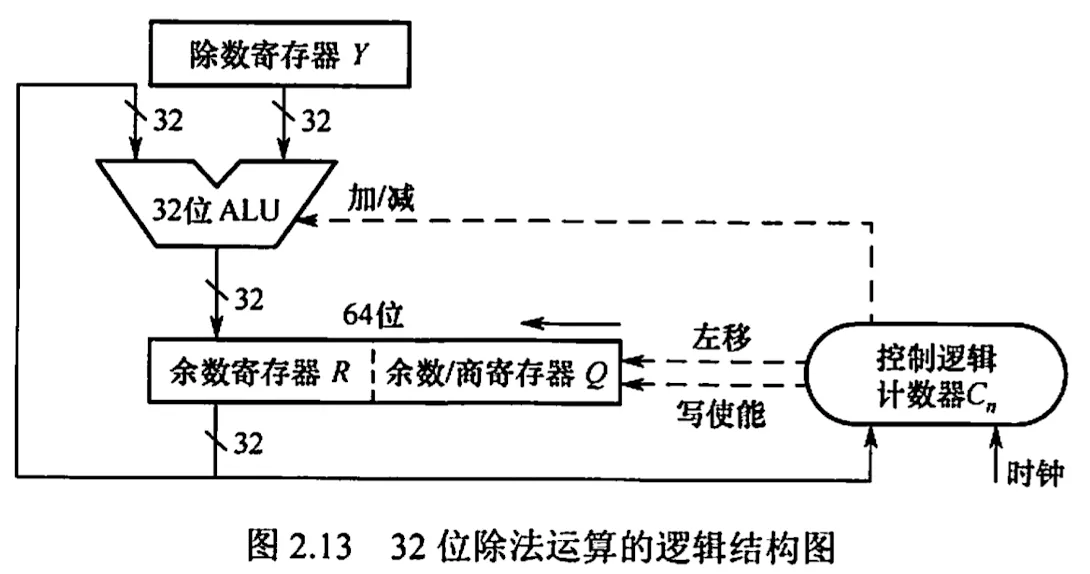
2.2.5. C 语言中的整数类型及类型转换
1. 有符号数和无符号数的转换
对于两者都能表示的数,希望转换过程中数值本身不发生变化。而对于转换后无法表示的数,大多会直接按照二进制代码翻译。
例如对于 short 类型的变量 ,在强制转换为 unsigned short 是变成了 65535,因为两者的二进制一致。
2. 不同字长整数之间的转换
- 当大字长变量强制类型转换时,会把多余的高位部分直接截断,低位直接赋值。
- 小字长转换时会对高位进行填充:无符号数会进行 0 扩展,带符号数会进行符号扩展。
2.2.6. 数据的存储和排列
1. 大端方式和小端方式
数据从低位到高位可以从左到右,也可以从右到左排列。通常用最低有效字节 LSB 和最高有效字节 MSB 来分别百鸟时数的低位和高位。在 32 位计算机中,一个 int 型变量 i 的机器数为 01234567H,其最高有效字节为 MSB=01H, 最低有效字节是 LSB=67H.
现代计算机大多采用字节编址,每个地址编号存放一个字节。对于 int 类型机器数 01234567H,大端方式和小端方式存放分别是以下的形式
| 地址 | 0800H | 0801H | 0802H | 0803H |
|---|---|---|---|---|
| 大端 | 01H | 23H | 45H | 67H |
| 地址 | 0800H | 0801H | 0802H | 0803H |
|---|---|---|---|---|
| 小端 | 67H | 45H | 23H | 01H |
2. 数据按照“边界对齐”方式存储
假设存储字长为 32 位,可按照字节、半字、字寻址。对于机器字长为 32 位的计算机,数据是对齐存放的,半字地址一定是 2 的整数倍,字地址是 4 的整数倍,这样无论所取的数据是字节、半字还是字,均可一次访存取出。这样边界对齐的存放方式可以提高取指令和取数的速度。
如果不按照边界对齐的方式存储,可以充分利用存储空间,但是半字长或字长的指令可能会存储在两个存储字中,需要两次访存,并且需要对高低字节进行调整、连接后才能得到正确的值,影响了效率。

2.3. 浮点数的表示与计算
2.3.1. 浮点数的表示
1. 表示格式
- 取 0 或 1
- 第 1 ~ 7 位为移码表示的阶码 ,偏置值为 64 ,阶码的位数反映浮点数的表示范围
- 第 8 ~ 31 位为 24 位二进制原码小数表示的尾数 ,尾数的位数反映浮点数的精度
- 基数 为 2
| 0 | 1 ~ 7 | 8 ~ 31 |
|---|---|---|
| 符号 | 阶码 | 尾数 |
2. 浮点数的表示范围
原码关于原点对称,故浮点数的范围也是关于原点对称的。

数据一旦上溢出,计算机必须中断运算操作,进行溢出处理。数据下溢出时,浮点数值趋于 0 ,计算机仅将其当作机器 0 处理。
3. 浮点数的规格化
尾数的位数决定浮点数的有效位数,有效位数越多,数据精度越高。为了在浮点数运算过程中尽可能多地保留有效数字的位数,使有效数字尽量占满尾数,必须在运算过程中对浮点数进行规格化操作,通过调整一个非规格化浮点数的尾数和阶码的大小,使非零的浮点数在尾数的最高位上保证是一个有效值。
- 左规:当运算结果的尾数的做高位不是有效位,即出现 的形式时,需要进行左规。尾数每左移一位、阶码减一,直至位数变为规格化形式为止。
- 右规:当运算结果的尾数有效位进到小数点签名,需要进行右规。将位数右移一位,阶码加一。需要右规时,只需进行一次。
原码表示的规格化尾数 的绝对值满足 . 若 ,则有
- 正数为 的形式,其最大值为 ,最小值为 . 尾数表示的范围是
- 负数表示为 的形式,最大值为 ,最小值为 . 尾数的表示范围为
4. IEEE 754 标准
| 位数 | 0 | 1 ~ 7 | 8 ~ 31 |
|---|---|---|---|
| 32 位单精度 | 符号 | 阶码 | 尾数 |
| 位数 | 0 | 1 ~ 11 | 12 ~ 63 |
|---|---|---|---|
| 64 位双精度 | 符号 | 阶码 | 尾数 |
短浮点数阶码用移码表示,阶码的偏置值为 ,其后 23 位是原码表示的尾数数值位。在浮点格式中表示的 23 位尾数是纯小数。对于规格化的二进制浮点数,数值最高位总是 “1”,为了能使尾数表示一位有效位。
例如,,规格化后为 ,整数部分的 1 不存储在 23 位尾数中。
短浮点数和长浮点数都采用隐藏尾数最高数位的方法,因此可以多表示一位尾数
长浮点数的偏置值为 1023. 存储浮点数阶码之前,偏置值要先加到阶码真值上。
IEEE 754 标准中,规格化短浮点数的真值为
规格化长浮点数的真值为
短浮点数 的取值为 1 ~ 254 , 为 23 位;长浮点数 取值为 1 ~ 2046 , 为 52 位。下表为规格化浮点数的表示范围。
| 格式 | 最小值 | 最大值 |
|---|---|---|
| 单精度 | ||
| 双精度 |
| 单精度 | 双精度 | |||||||
|---|---|---|---|---|---|---|---|---|
| 值类型 | 符号 | 阶码 | 尾数 | 值 | 符号 | 阶码 | 尾数 | 值 |
| 正 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 负 0 | 1 | 0 | 0 | -0 | 1 | 0 | 0 | -0 |
| 正无穷大 | 0 | 255 | 0 | inf | 0 | 2047 | 0 | inf |
| 负无穷大 | 1 | 255 | 0 | -inf | 1 | 2047 | 0 | -inf |
5. 顶点、浮点表示的区别
数值表示的范围
若定点数和浮点数字长相同,则浮点数表示法能够表示的数值范围远大于定点表示法
精度
对于字长相同的定点数和浮点数,浮点数的范围较大,但精度降低
数的运算
浮点数包括阶码和尾数两部分,两部分都需要计算,而且运算结果要求规格化,所以浮点运算比顶点运算复杂
溢出问题
在定点运算中,当运算结果超出数的表示范围,发生溢出;浮点运算中,运算结果超出尾数表示范围不一定溢出,只有规格化后阶码超出所能表示的范围时,才发生溢出
2.3.2. 浮点数的加减运算
阶码和尾数分开进行
1. 对阶
使两个操作数的小数点对齐,即使得两个数的阶码相等。先求阶差,然后以小阶向大阶看齐的原则,将小阶码的尾数右移一位,阶加一,直到两个数的阶码相等。尾数右移时,舍弃掉有效位会产生误差,影响精度。
2. 尾数求和
将对阶后的尾数按定点数相加减运算规则运算。运算后的尾数不一定是规格化的,因此需要进一步规格化。
3. 规格化
IEEE 754 的尾数形式为 ,位数相加可能会有下面的结果
右规
当结果为第一种情况时,尾数右移一位,阶码加一。尾数右移时,最高位 1 被移到小数点前一位作为隐藏位,最后一位移出,要考虑舍入。
左规
当结果为第二种情况时,尾数每左移一位,阶码减一。可能需要左规多次,知道将第一位移到小数点的左边。
4. 舍入
在对阶和尾数右规时,可能会对尾数进行右移,为保证运算精度,一般将低位移出的两位保留下来,参加中间过程的计算,最后将运算结果进行舍入,还原为 IEEE 754 格式。
- 0 舍 1 入法:类似十进制的四舍五入。运算结果保留位的最高位为 0 ,舍去;最高位为 1 ,则在尾数的末位加一。这样可能使尾数溢出,此时需要再进行一次右规
- 恒置 1 法:只要因移位而丢失的位中有 1 ,就把尾数位置 1 ,而不管原来是 0 还是 1
- 截断法:直接截取所需位数,丢弃后面的位
5. 溢出判断
在尾数规格化和尾数舍入时,可能会对阶码执行加减运算。若一个正指数超过了最大允许值 (127 或 1023),则发生指数上溢,产生异常。若一个负指数超过了最小允许值 (-149 或 -1074),则发生指数下溢,通常按照机器 0 处理。
浮点数的溢出是按照指数来判断的。
6. C 语言中的浮点数类型
在类型转换时,可能会出现精度损失或范围溢出。
- int 转 float 不会发生溢出,但 float 的精度只有 24 位,当 int 型整数的第 24 ~ 31 位非 0 时,无法精确转为 24 位浮点数的尾数
- double 转 float 因为后者表示的范围更小,精度更低,可能会溢出和精度丢失
- float 或 double 转 int 时,因为 int 没有小数部分,因此会向 0 方向截断(仅保留整数),发生舍入