第 4 章 指令系统
内容
- 指令格式的基本概念
- 指令格式
- 寻址方式
- 数据的对齐和大/小端存放方式
- CISC 和 RISC 的基本概念
- 高级语言程序与机器代码时间的对应
- 编译器、汇编器与链接器的基本概念
- 选择结构语句的机器级表示
- 循环结构语句的机器级表示
- 过程(函数)调用对应的机器级表示
4.1. 指令格式
指令(机器指令)是指示计算机执行某种操作的命令。一台计算机的所有指令的集合构成该机的指令系统,也称指令集。指令系统是计算机的主要属性,位于硬件和软件的交界面上。
4.1.1. 指令的基本格式
一条指令就是机器语言的一个语句,是一组有意义的二进制代码。一条指令通常包括操作码字段和地址码字段。
- 操作码指出指令中应该执行什么性质的操作以及具有何种功能,是识别指令、了解指令功能及区分操作数地址内容的组成和使用方法等的关键信息。
- 如指出是算术运算指令,还是跳转指令等
- 地址码给出倍操作的信息(指令或数据)的地址,包括参加运算的一个或多个操作数所在的地址、运算结果的保存地址、程序的转移地址、倍调用的子程序的入口地址等。
| 操作码字段 | 地址码字段 |
|---|
指令长度是指一条指令中所包含的二进制代码的位数。指令字长取决于操作码的长度、操作数地址码的长度和操作数地址的个数,与机器字长没有固定的关系。
通常,把指令长度等于机器字长的指令称为单字长指令,指令长度等于半个机器字长的指令称为半字长指令,指令长度等于两个机器字长的指令称为双子长指令。
- 在一个指令系统中,若所有指令的长度相等,则称为定长指令字结构。定字长指令的执行速度快,控制简单。
- 若各种指令的长度随功能而异,则称为变长指令字结构。
因为主存一般是按字节编址的,所以指令字长多为字节的整数倍。
1. 零地址指令
只给出操作码 OP,没有显式地址,有两种可能:
- 不需要操作数的指令,如空指令、停机指令、关中断指令等
- 零地址的运算类指令仅用在堆栈计算机中。通常参与运算的两个操作数隐含的从栈顶和次栈顶弹出,送到运算器运算,再隐含的压栈
2. 一地址指令
| OP |
|---|
- 只有目的操作数的但操作数指令,按 地址取操作数,进行 OP 操作后,结果放回原地址,即 ,如自增,求反等
- 隐含约定目的地址的双操作数指令,按地址 可取源操作数,指令可隐含约定另一个操作数由 ACC (累加器) 提供,运算结果也放在 ACC 中,即
3. 二地址指令
| OP |
|---|
指令含义
对于常用的算术逻辑运算指令,往往要求两个操作数,目的操作数地址用于保存本次运算结果。
4. 三地址指令
| OP | 结果 |
|---|
指令含义
5. 四地址指令
| OP | 结果 | 下址 |
|---|
指令含义 , = 下一条要执行指令的地址
4.1.2. 定长操作码指令格式
定长操作码指令在指令字的最高位部分分配固定的若干位(定长)表示操作码。一般 位操作码字段的指令系统最大能表示 条指令。定长操作码对于简化计算机硬件设计,提高指令译码和识别速度很有利。
4.1.3. 扩展操作码指令格式
为了在指令字长有限的前提下仍保持比较丰富的指令种类,可采取可变长度操作码,即全部指令的操作码字段的位数不固定,且分散的放在指令字的不同位置上。这样将增加指令译码和分析的难度,使控制器的设计复杂化。
常见的变长操作码方法是扩展操作码,它使操作码的长度随地址码的减少而增加,不同地址数的指令可具有不同长度的操作码,从而在满足需要的前提下,有效地缩短指令字长。

Caution
- 不允许短码是长码的前缀,即短操作码不能与长操作码的前面部分的代码相同
- 各指令的操作码一定不能重复
4.1.4. 指令的操作类型
指令的操作类型按功能可以分为下面几种
1. 数据传送
- 寄存器之间传送
MOV - 从内存单元读取数据到 CPU 寄存器
LOAD - 从 CPU 寄存器写数据到内存单元
STORE
2. 算术和逻辑运算
加 ADD,减 SUB,比较 CMP,乘 MUL,除 DIV,加一 INC,减一 DEC,与AND,或 OR,取反 NOT,异或 XOR 等
3. 移位操作
- 算术移位
- 逻辑移位
- 循环移位
4. 转移操作
- 无条件转移 JMP
- 条件转移 BRANCH
- 调用 CALL
- 返回 RET
- 陷阱 TRAP
调用指令和转移指令的区别
- 执行调用指令时必须保存下一条指令的地址(返回地址),当子程序执行结束,根据返回地址返回到主程序继续执行
- 转移指令不返回执行
5. 输入输出操作
用于完成 CPU 与外部设备交换数据或传送控制命令及状态信息。
4.2. 指令的寻址方式
指寻找指令或操作数有效地址的方式,即确定本条指令的数据地址及下一条待执行指令的地址的方法。寻址方式分为指令寻址和数据寻址两大类。
指令中的地址码字段并不代表操作数的真实地址,这种地址称为形式地址 (A)。形式地址结合寻址方式,可以计算出操作数在存储器中的真实地址,这种地址被称为有效地址 (EA)。
4.2.1. 指令寻址和数据寻址
1. 指令寻址
寻找下一条将要执行的指令地址称为指令寻址
方式有两种
- 顺序寻址:通过程序计数器 PC 加一,自动形成下一条指令的地址
- 跳跃寻址:通过转移类指令实现。下一条指令不由 PC 自动给出,而由本条指令给出下调指令地址的计算方式。是否跳跃可能收到状态寄存器和操作数的控制
- 跳跃的地址分为绝地地址和相对地址
- 跳跃的结果是当前指令修改 PC 值,所以下一条指令仍然通过 PC 给出
2. 数据寻址
数据寻址是指如何在指令中表示一个操作数的地址,如何用这种表示得到操作数或怎样计算出操作数地址
数据寻址的方式较多,为区别各种方式,通常在指令字中设置一个字段,用来指明属于哪一种寻址方式。
| 操作码 | 寻址特征 | 形式地址 |
|---|
4.2.2. 常见的数据寻址方式
1. 隐含寻址
指令不明显的给出操作数的地址,而在指令中隐含操作数的地址。
单地址的指令格式就不明显地在地址字段中指出第二个操作数的地址,二规定累加器 ACC 作为第二操作数地址,指令格式明显指出的仅是第一操作数的地址。

优点是有利于缩短指令字长;缺点是需增加存储操作数或隐含地址的硬件。
2. 立即寻址
指令的地址字段指出的是操作数本身,而不是操作数的地址。又称立即数,采用补码表示。
优点是指令在执行阶段不访问主存,指令执行时间最短;缺点是 A 的位数限制了立即数的范围
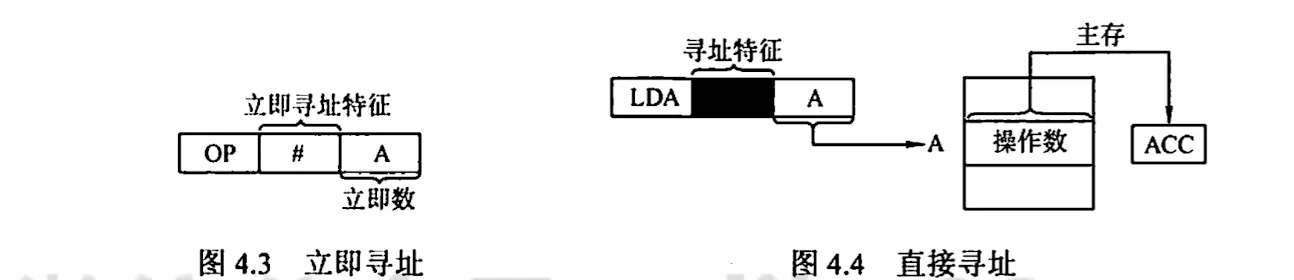
3. 直接寻址
指令字中的形式地址 A 是操作数的真实地址 EA
4. 间接寻址
间接寻址是相对于直接寻址而言的,指令的地址字段给出的形式地址不是操作数的真正地址,而是操作数有效地址所在的存储单元的地址,即 EA = (A)
间接寻址可以是一次间接,也可以是多次间接
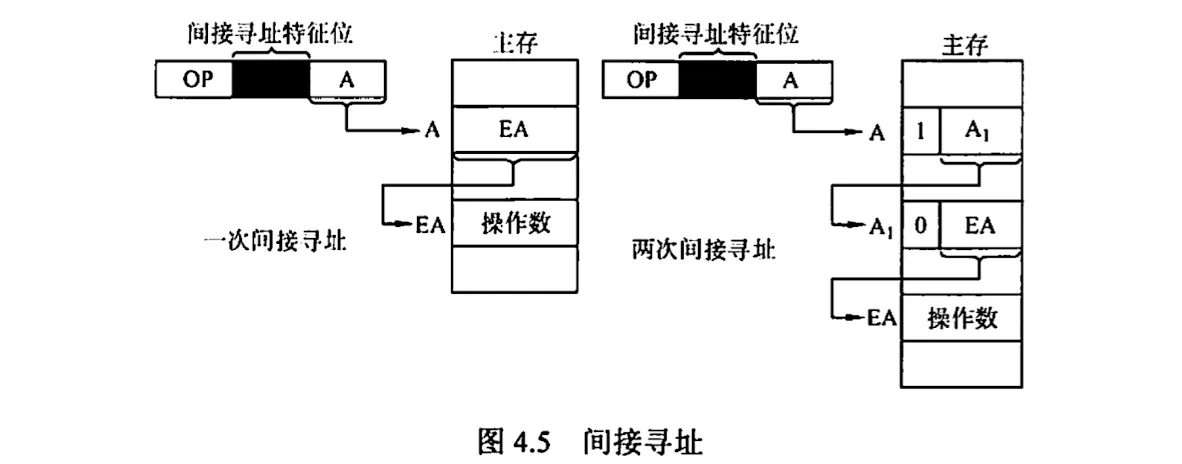
上图中,主存字第一位为 1 时,表示取出的仍不是操作数的地址,即多次间接寻址;主存字第一位为 0 时,表示取得的是操作数地址。
间接寻址的优点是可以扩大寻址范围,编译编址程序(用间接寻址可方便地完成子程序的返回);缺点是指令在执行阶段要多此访存(一次间接寻址需两次方寸,多次间接寻址需根据存储字的最高位确定访存字数)。
由于访问速度过慢,这种寻址方式并不常用,一般扩大寻址范围时,通常指寄存器间接寻址。
5. 寄存器寻址
是指在指令字中直接给出操作数所在的寄存器编号,即 EA = ,其操作数在由 所指的寄存器内。
优点是指令在执行阶段不访问主存,只访问寄存器,因寄存器数量较少,对应地址码长度较小,使得指令字短且因不用访存,所以执行速度快,支持向量/矩阵运算;缺点是寄存器价格昂贵,计算机中的寄存器个数有限。
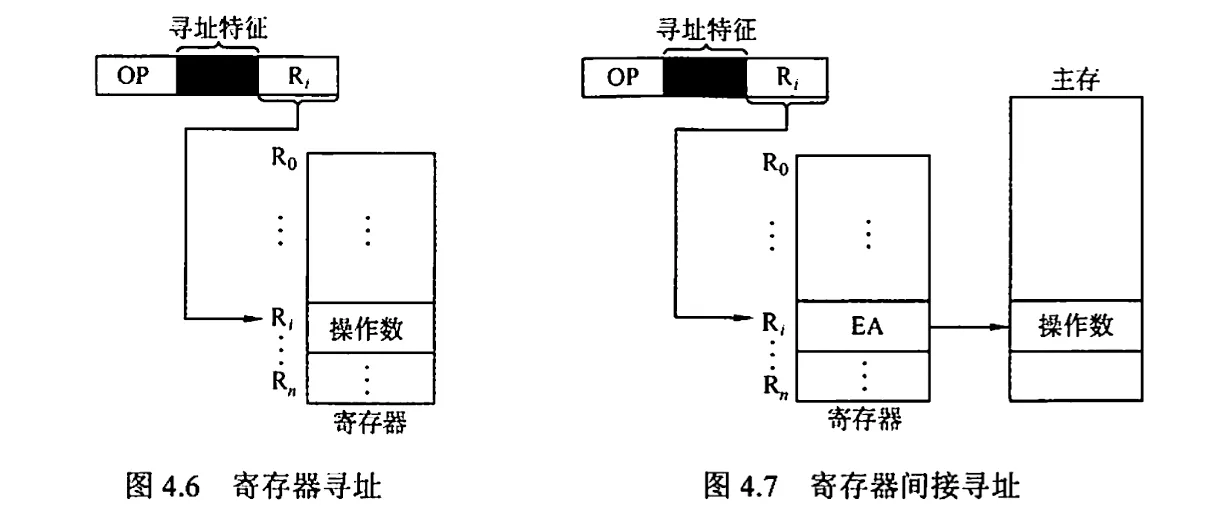
6. 寄存器间接寻址
在寄存器 中给出的不是操作数,而是操作数所在主存单元的地址,即 EA = ()
特点:与一般间接寻址相比速度更快,但指令的执行阶段需要访问主存(因为操作数在主存)。
7. 相对寻址
相对寻址是把 PC 的内容加上指令格式中的形式地址 A 二形成操作数的有效地址,即 EA = (PC) + A,其中 A 是相当于当前指令地址的位移量,可正可负,补码表示。
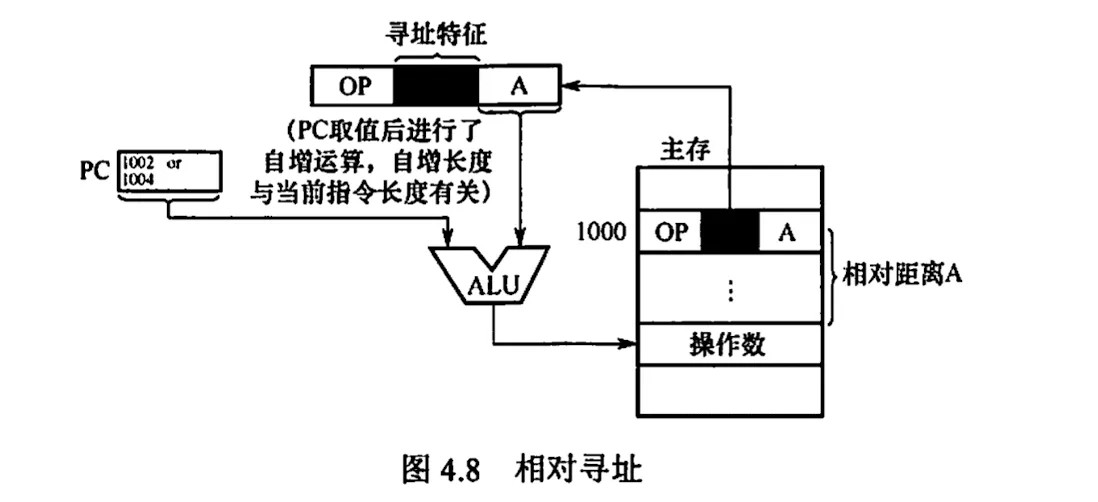
A 的位数决定操作数的寻址范围
相对寻址的优点是操作数的地址不是固定的,随 PC 的值变化而变化,且与指令地址之间总是相差一个固定值,因此便于程序浮动。相对寻址广泛与转移指令。
对于转移指令 JMP A,当 CPU 从存储器中取出一字节时,会自动执行 . 若转移指令的地址为 X,且占 2B,在取出该指令后,PC 的值会增 2,即 ,这样在执行完该指令后,会自动跳转到 的地址继续执行。
8. 基址寻址
基址寻址是指将 CPU 中基址寄存器 BR 的内容加上指令格式中的形式地址 A 二形成操作数的有效地址,即 EA = (BR) + A. 其中基址寄存器既可采用专用寄存器,又可采用通用寄存器。
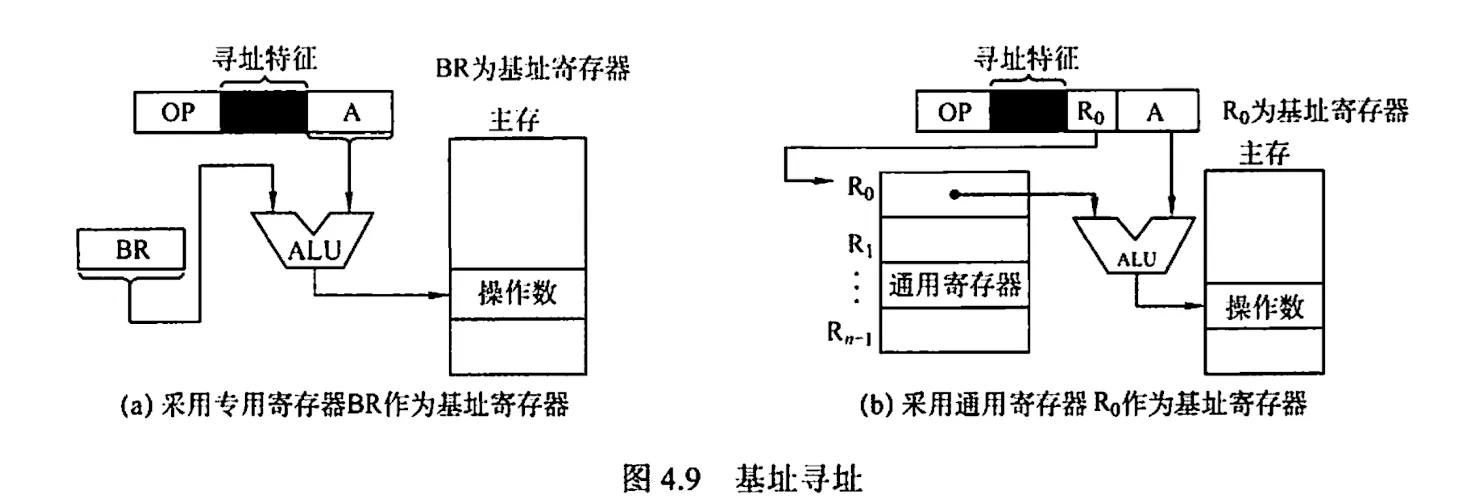
基址寄存器是面向操作系统的,其内容由操作系统或管理程序确定,主要用于解决程序逻辑空间与存储器物理空间的无关性。在程序执行过程中,基址寄存器的内容不变(作为基地址),形式地址可变(作为偏移量)。采用通用寄存器作为基址寄存器时,可由用户决定哪个寄存器作为基址寄存器,但其内容仍由操作系统确定。
优点
- 可扩大寻址范围(基址寄存器的位数大于形式地址 A 的位数)
- 用户不必考虑自己的程序于主存的哪个空间区域,因此有利于多道程序设计,并可用于编制浮动程序,但偏移量(形式地址 A )的位数较短
9. 变址寻址
有效地址 EA = 变址寄存器 IX 的内容 + 形式地址 A,即 EA = (IX) + A,其中 IX 为变址寄存器(专用),也可用通用寄存器作为变址寄存器。
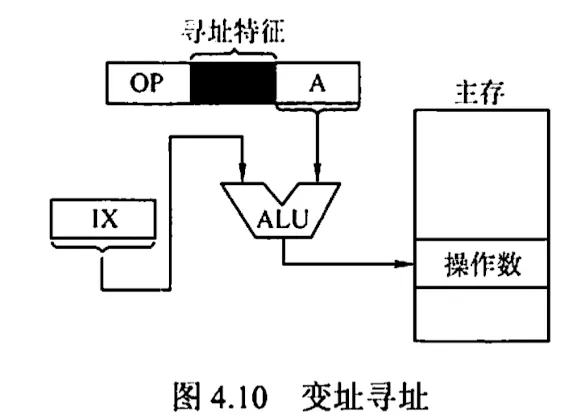
变址寄存器是面向用户的,在程序执行过程中,变址寄存器的内容可由用户改变(作为偏移量),形式地址 A 不变(作为基地址)
优点
- 可扩大寻址范围(变址寄存器的位数大于形式地址 A 的位数)
- 在书组处理过程中,可设定 A 为数组的首地址,不断改变变址寄存器 IX 的内容,便可很容易形成数组中任一数据的地址,特别适合编制循环程序
偏移量(变址寄存器 IX )的位数足以表示整个存储空间。
变址寻址和基址寻址的区别
- 基址寻址
- 面向系统,主要用于为多道程序或数据分配存储空间
- 内容通常由操作系统或管理程序确定,在程序的执行过程中其值不可变,而指令字中的 A 是可变的
- 变址寻址
- 立足于用户,主要处理数组问题
- 内容由用户设定,在程序执行过程中其值可变,而指令字中的 A 不可变
10. 堆栈寻址
堆栈是后进先出原则管理的存储区,该存储器中读/写单元的地址是用一个特定的寄存器给出的,该寄存器称为堆栈指针 SP。堆栈可分为硬堆栈和软堆栈。
寄存器堆栈称为硬堆栈,成本较高,不适合做大容量的堆栈。
从主存中划出一段区域来做堆栈是最合算且最常用的方法,称为软堆栈。
在采用堆栈结构的计算机系统中,大部分指令表面上都表现为无操作数指令的形式,因为操作数地址都隐含了 SP。通常,在读/写堆栈中的一个单元的前后都伴有自动完成对 SP 内容的增量或减量操作。
| 寻址方式 | 有效地址 | 访存次数 |
|---|---|---|
| 隐含寻址 | 程序指定 | 0 |
| 立即寻址 | A 为操作数 | 0 |
| 直接寻址 | EA = A | 1 |
| 一次间接寻址 | EA = (A) | 2 |
| 寄存器寻址 | EA= | 0 |
| 寄存器间接一次寻址 | EA = () | 1 |
| 相对寻址 | EA = (PC) + A | 1 |
| 基址寻址 | EA = (BR) + A | 1 |
| 变址寻址 | EA = (IX) + A | 1 |
4.3. 程序的机器级代码表示
4.3.1. 常用汇编指令
1. 相关寄存器
x86 处理器中有 8 个 32 位通用寄存器
- EAX 累加器
- EBX 基址寄存器
- ECX 计数寄存器
- EDX 数据寄存器
- ESI
- EDI 变址寄存器
- EBP 堆栈基指针
- ESP 堆栈顶指针
2. 汇编指令格式
AT&T 和 Intel
3. 常用指令
数据传送指令
- mov
- push
- pop
算术和逻辑运算指令
- add/sub
- inc/dec
- imul
- idiv
- and/or/xor
- not
- neg
- shl/shr
控制流指令
- jmp
- jcondition
- cmp/test
- call/ret
4.3.2. 过程调用的机器级表示
调用者 P 和被调用者 Q
- P 将入口参数(实参)放在 Q 能访问到的地方
- P 将返回地址存到特定的地方,然后将控制转移到 Q
- Q 保存 P 的现场(通用寄存器的内容),并为自己的非静态局部变量分配空间
- 执行 Q
- Q 恢复 P的现场(通用寄存器的内容),释放局部变量的空间
- Q 取出返回地址,将控制转移到 P
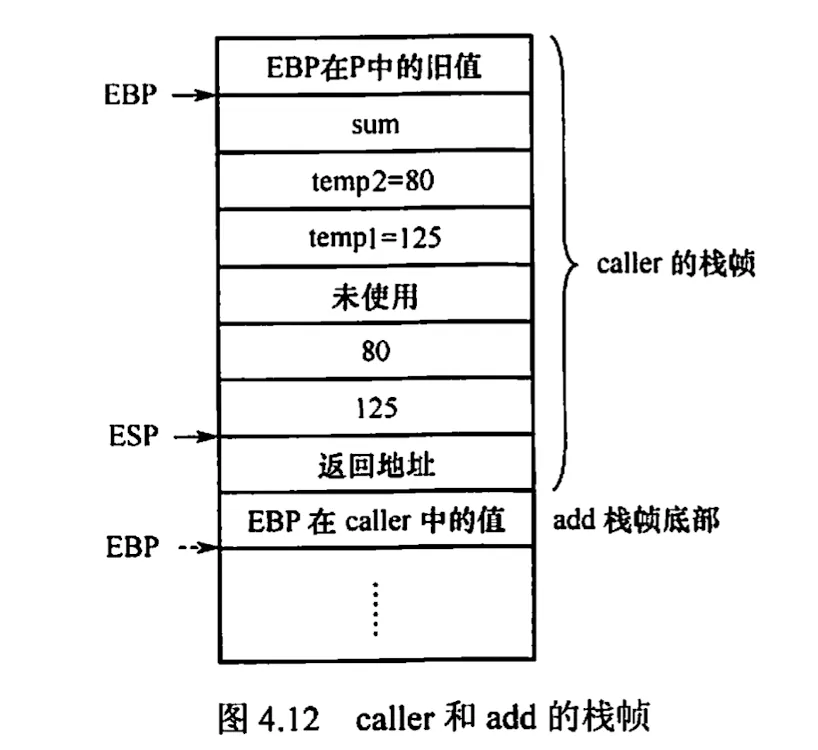
int add (int x, int y) { return x + y;}int caller() { int temp1 = 125; int temp2 = 80; int sum = add(temp1, temp2); return sum;}caller: pushl %ebp movl %esp, %ebp subl $24, %esp movl $125, -12(%ebp) ; M[R[ebp]-12] <- 125 movl $80, -8(%ebp) ; M[R[ebp]-8] <- 80 movl -8(%ebp), %eax ; R[eax] <- M[R[ebp]-8] mov %eax, 4(%esp) ; M[R[esp]+4] <- R[eax] temp2 入栈 movl -12(%ebp), %eax ; R[eax] <- M[R[ebp]-12] movl %eax, (%esp) ; M[R[esp]] <- R[eax] temp1 入栈 call add ; 调用 add movl %eax, -4(%ebp) ; M[R[ebp]-4] <- R[eax] 返回值给 sum movl -4(%ebp), %eax ; R[eax] <- M[R[ebp]-4] sum 作为返回值 leave ret指令通过基址+偏移的方式来找到实际的操作数
4.3.3. 选择语句的机器级表示
条件码(标志位)
- CF 进借位标志
- ZF 零标志
- SF 符号标志
- OF 溢出标志
if 语句
if (test_expr) then_statement;else else_statement;可以被翻译为 goto 语句的形式
t = test_expr; if (!t) goto LF; then_statement; goto Done;LF: else_statement;done:switch 语句

跳转表属于只读数据,数据段属性为 .rodata,并且跳转表中的每个跳转地址都必须在 4 字节边界上,即 align 4 方式,每个表项的偏移量分别是 0, 4, 8, 12, 16, 20, 24, 28,即偏移量等于 索引值 × 4
偏移量与跳转表的首地址(.L8 指定)相加就是转移目标地址。
4.3.4. 循环语句的机器级表示
do-while 循环
do { body_statement;} while (test_expr);翻译为
loop: body_statement; t = test_expr; if (t) goto loop;while 循环
while (test_expr) { body_statement;}翻译为
t = test_expr; if (!t) goto done;loop: body_statement; t = test_expr; if (t) goto loop;done:for 循环
for (init_expr; test_expr; update_expr) body_statement;相当于
init_expr;while (test_expr) { body_statement; update_expr;}翻译为
init_expr; t = test_expr; if (!t) goto done;loop: body_statement; update_expr; t = test_expr; if (t) goto loop;done:4.4. CISC 和 RISC 的基本概念
4.4.1. 复杂指令系统计算机 CISC
特点
- 指令系统庞大,指令数目一般在 200 条以上
- 指令长度不固定,指令格式多,寻址方式多
- 可以方寸的指令不受限制
- 各种指令使用频度相差大
- 各种指令执行时间相差很大,大多数指令需多个时钟周期才能完成
- 控制器大多数采用微程序控制,有些指令非常复杂,以至于无法采用硬连线控制
- 难以用优化编译生成高校的目标代码程序
4.4.2. 精简指令系统计算机 RISC
中心思想是要求指令系统简化,尽量使用寄存器-寄存器操作指令,指令格式力求一致
主要特点
- 选取是与偶那个频率最高的一些简单指令,复杂指令的功能由简单指令的组合来实现
- 指令长度固定,指令格式种类少,寻址方式种类少
- 只有 Load/Store 指令方寸,其余指令的操作都在寄存器之间进行
- CPU 中通用寄存器的数量相当多
- RISC 一定采用指令流水线技术,大部分指令在一个时钟周期内完成
- 以硬布线控制为主,不用或少用微程序控制
- 特别重视编译优化工作,以减少程序执行时间
从指令系统兼容新看,CISC 大多能实现软件兼容,即高档机包含了低档机的全部指令,并可加以扩充。RISC 简化了指令系统,指令条数少,格式也不同于老机器,因此大多数 RISC 机不能与老机器兼容。
由于 RISC 具有更强的实用性,因此应该是未来处理器的发展方向。
早期很多软件都是根据 CISC 设计的(因为 Intel ),单纯的 RISC 无法兼容。现代 CISC 结构的 CPU 已经融合了很多 RISC 的成分,差距已经越来越小。CISC 可以提供更多功能,这是程序设计所需要的。
4.4.3. 两者比较
和 CISC 相比,RISC 的优点体现在以下几点
- RISC 更能充分利用 VLSI 芯片的面积。CISC 的控制器大多采用微程序控制,其控制存储器在 CPU 芯片内所占的面积达 50% 以上,而 RISC 控制器采用组合逻辑控制,其硬布线逻辑只占 CPU 芯片面积的 10% 左右。
- RISC 更能提高运算速度。RISC 的指令数、寻址方式和指令格式种类少,又设有多个通用寄存器,采用流水线技术,运算速度更快,大多指令在一个时钟周期内完成。
- RISC 便于设计,可降低成本,提高可靠性。RISC 指令系统简单,因此机器设计周期短;逻辑简单,可靠性高。
- RISC 有利于编译程序代码优化。RISC 指令类型少,寻址方式少,使编译程序容易选择更有效的指令和寻址方式,并适当的调整指令顺序,使得代码执行更高效化。
| CISC | RISC | |
|---|---|---|
| 指令系统 | 庞大,复杂 | 简单,精简 |
| 指令数目 | 一般大于 200 条 | 一般小于 100 条 |
| 指令字长 | 不固定 | 定长 |
| 可访存指令 | 不加限制 | 只有 Load/Store |
| 各种指令执行时间 | 相差较大 | 绝大多数在一个周期内完成 |
| 各种指令使用频度 | 相差很大 | 都比较常用 |
| 通用寄存器数量 | 较少 | 多 |
| 目标代码 | 难以用优化编译生成高校的目标代码程序 | 采用优化的编译程序,生成代码较为高效 |
| 控制方式 | 绝大多数为微程序控制 | 绝大多数为组合逻辑控制 |
| 指令流水线 | 可以通过一定方式实现 |