第六次
1. 启动
1.1. 检查 hosts
172.22.0.3 master172.22.0.4 slave1172.22.0.5 slave21.2. 启动 hbase 服务
1.2.1. 启动 hdfs
[lc@master ~] start-dfs.sh同时,保证 hdfs 中有一个 hbase 的目录项,若没有,则需要通过下面的命令创建
[lc@master ~] hadoop fs -mkdir /hbase
1.2.2. 启动 hbase
[lc@master bin] ./start-hbase.sh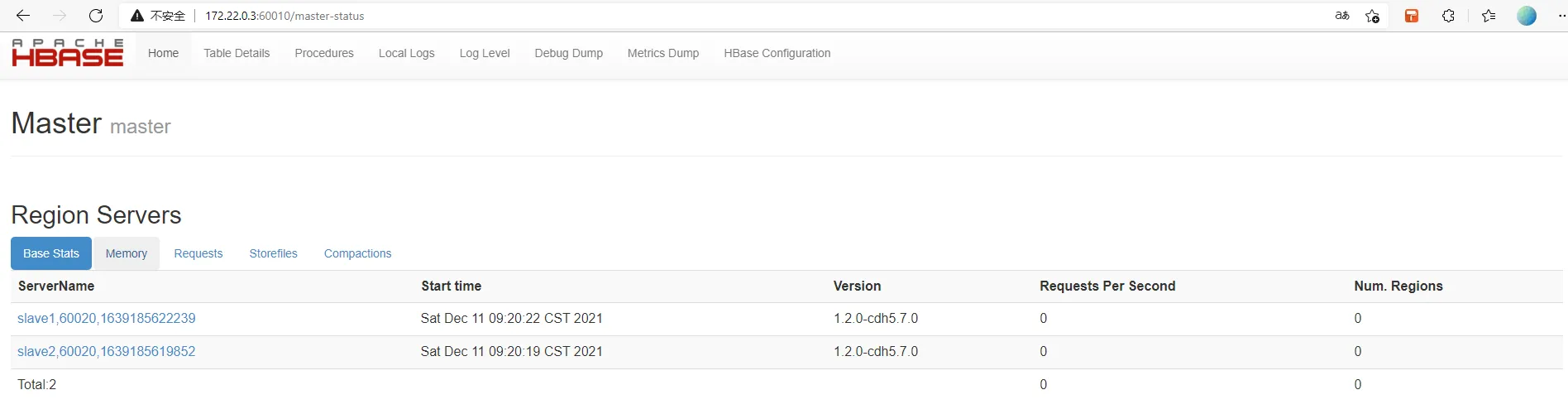
2. API 编程
2.1. 通过 maven 在项目中添加 hbase 依赖
pox.xml 的 <dependencies> 中加入下面的项,并刷新 maven
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.2.0</version></dependency>2.2. 尝试通过 API 连接 hbase
2.2.1. 在 hbase shell 中尝试建表
hbase(main):002:0> create 'tab1','f1','f2'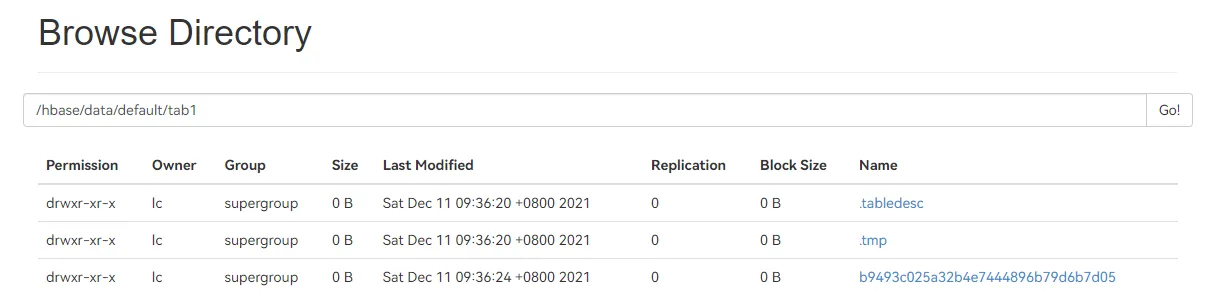
2.2.2. 编写 Java 代码
package cn.edu.nnu;
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Connection;import org.apache.hadoop.hbase.client.ConnectionFactory;import org.apache.hadoop.hbase.client.HBaseAdmin;
public class HbaseDemo { public static void main(String[] args) { Configuration conf = null; Connection conn = null; HBaseAdmin admin = null; try { conf = HBaseConfiguration.create(); // 1. 对于第二个参数,如果在本机的 hosts 中已经配置了 172.22.0.3 master 等等项 // 则可以直接用主机名即可,否则需要填写主机的 IP,例如 `172.22.0.3:2181` // 2. 如果在 `/hbase/conf/hbase-site.xml` 中 clientPort 写入了 2181 的端口号 // 则按照下面来写即可,否则还需要在主机名后加上端口号,例如 `master:2181` conf.set("hbase.zookeeper.quorum", "master,slave1,slave2"); conn = ConnectionFactory.createConnection(conf); admin = (HBaseAdmin) conn.getAdmin(); if (admin.tableExists("tab1")) { System.out.println("tab1 exists!"); } else { System.out.println("tab1 noexists!"); } System.out.println("ok"); } catch (Exception ex) { System.out.println("fail"); } finally { try { assert conn != null; conn.close(); } catch (Exception ex) { ex.printStackTrace(); } } }}2.2.3. 通过 API 编程添加表和数据
创建表
将 admin, conf, conn 放入类的静态成员变量,并在 main 中初始化。
private static boolean existTable(String tableName) throws IOException { if (admin.tableExists(tableName)) { System.out.println(tableName + "已存在"); return true; } else { System.out.println(tableName + "不存在"); return false; }}
private static void createTable(String tabName, String... cfs) throws IOException { if (existTable(tabName)) { return; } HTableDescriptor tab = new HTableDescriptor( TableName.valueOf(tabName)); for (String cf : cfs) { HColumnDescriptor colDesc = new HColumnDescriptor(cf); // 创建列 tab.addFamily(colDesc); // 添加列族 } admin.createTable(tab); // 创建表 System.out.println("Create Success!");}// maincreateTable("tab2", "cf1", "cf2");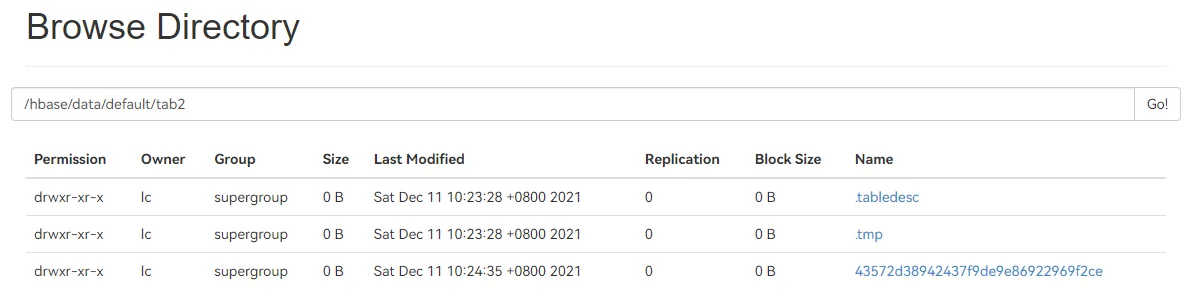
添加数据
private static void putTest(String tabName, String rowKey, Map<String, List> data) throws IOException { if (!existTable(tabName)) { // 判断表是否存在 return; } Table tab = conn.getTable(TableName.valueOf(tabName)); // 获取表对象 Put put = new Put(rowKey.getBytes(StandardCharsets.UTF_8)); for (Map.Entry<String, List> entry : data.entrySet()) { // 逐个获取 data 中的数据 String cf = entry.getKey(); List val = entry.getValue(); for (int i = 0; i < val.size(); i += 2) { put.addColumn( // 添加列 cf.getBytes(StandardCharsets.UTF_8), // 列名 ((String) val.get(i)).getBytes(StandardCharsets.UTF_8), // 列项 ((String) val.get(i + 1)).getBytes(StandardCharsets.UTF_8) // 数据 ); } } tab.put(put); // 放入数据}
public static void main(String[] args) { try { // ... 初始化 Map<String, List> data = new HashMap<>(); // 创建 Map 对象 data.put("cf1", Arrays.asList("name", "lc", "age", "20")); // cf1 列族的项 data.put("cf2", Arrays.asList("java", "100", "hadoop", "50")); // cf2 列族的项 putTest("tab2", "rk001", data); // 静态成员方法添加数据 System.out.println("ok"); } catch (Exception ex) { System.out.println("fail"); } finally { // ... 后续处理 }}
读取数据
// maingetTest("tab2", "rk001", "cf1:name");// get 输出 lcprivate static void getTest(String tabName, String rowKey, String cfName) throws IOException { Table tab = conn.getTable(TableName.valueOf(tabName)); Get get = new Get(rowKey.getBytes(StandardCharsets.UTF_8)); Result result = tab.get(get); Cell[] cells = result.rawCells(); for (int i = 0; i < cells.length; i++) { Cell cell = cells[i]; String name = new String(CellUtil.cloneFamily(cell)) + ":" + new String(CellUtil.cloneQualifier(cell)); if (name.equals(cfName)) { // 只读取一条 String val = new String(CellUtil.cloneValue(cell)); System.out.println(val); break; } }}// mainscanTest("tab2");// scanprivate static void scanTest(String tabName) throws IOException { Table tab = conn.getTable(TableName.valueOf(tabName)); Scan scan = new Scan(); ResultScanner scanner = tab.getScanner(scan); // 读取全部 while (true) { Result result = scanner.next(); if (result == null) { break; } Cell[] cells = result.rawCells(); for (int i = 0; i < cells.length; i++) { Cell cell = cells[i]; String rk = new String(CellUtil.cloneRow(cell)); String name = new String(CellUtil.cloneFamily(cell)) + ":" + new String(CellUtil.cloneQualifier(cell)); String val = new String(CellUtil.cloneValue(cell)); System.out.println(rk + "\t" + name + "\t" + val); } }}// 输出rk001 cf1:age 20rk001 cf1:name lcrk001 cf2:hadoop 50rk001 cf2:java 1003. MapReduce 集成 HBase
3.1. 前期准备
3.1.1. 拷贝 hbase-site.xml 配置文件到 hadoop 的配置目录下。
cp hbase/conf/hbase-site.xml hadoop/etc/hadoop/3.1.2. 编辑 hadoop/etc/hadoop/hadoop-env.sh
[lc@master hadoop]$ pwd/home/lc/hadoop/etc/hadoop[lc@master hadoop]$ vi hadoop-enc.shexport HADOOP_CLASSPATH=$HADOOP_CLASSPATH:~/hbase/lib/*![]()
3.1.3. 重启 hbase 和 hdfs
3.1.4. 测试命令
hadoop jar hbase/lib/hbase-server-1.2.0-cdh5.7.0.jar rowcounter tab2
3.2. 综合应用
3.2.1. 批量导入数据
在 hbase 中创建 music 表
create 'music','info'组织数据文件并上传到 hdfs 的 /musicdata
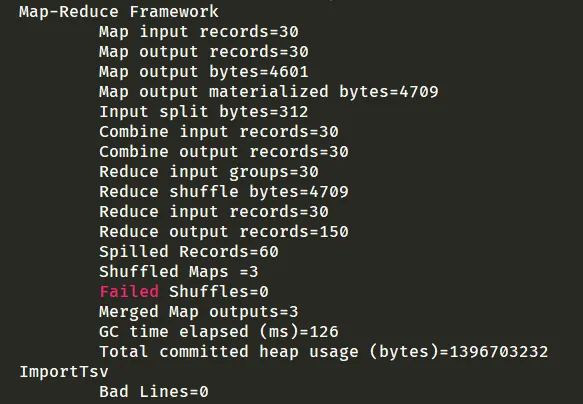
hadoop fs -put code/hadoop/music1.txt /musicdata/hadoop fs -put code/hadoop/music2.txt /musicdata/hadoop fs -put code/hadoop/music3.txt /musicdata/使用 hbase 的 importtsv 工具将数据导入
以下命令在一行内
[lc@master ~] hadoop jar ~/hbase/lib/hbase-server-1.2.0-cdh5.7.0.jar importtsv -Dimporttsv.bulk.output=tmp -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:singer,info:gender,info:rhythm,info:terminal music /musicdata| 参数 | 含义 |
|---|---|
-Dimporttsv.bulk.output=tmp | 表示输出文件夹 |
-Dimporttsv.columns | 指定数据对应的含义 |
HBASE_ROW_KEY | 表示作为行键 |
music | 表示要存储的表名 |
/musicdata | 表示输入目录或文件 |
-Dcreate.table=yes | 表不存在时创建表 |

载入数据
使用 hbase 的 completebulkload 工具将数据载入 HRegion 中
hadoop jar ~/hbase/lib/hbase-server-1.2.0-cdh5.7.0.jar completebulkload tmp music| 参数 | 含义 |
|---|---|
tmp | 上一步的输出目录 |
music | 目标表 |
通过 hbase shell 查看表内的详细信息

3.2.2. Hbase MapReduce API
添加依赖
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.2.0</version></dependency><dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-hadoop-compat</artifactId> <version>1.2.0</version></dependency>3.2.3. 单一 Mapper 示例
编写代码,打包为 jar,上传到虚拟机后运行
hadoop jar bd-1.0-SNAPSHOT.jar cn.edu.nnu.hbasemr.HbaseApp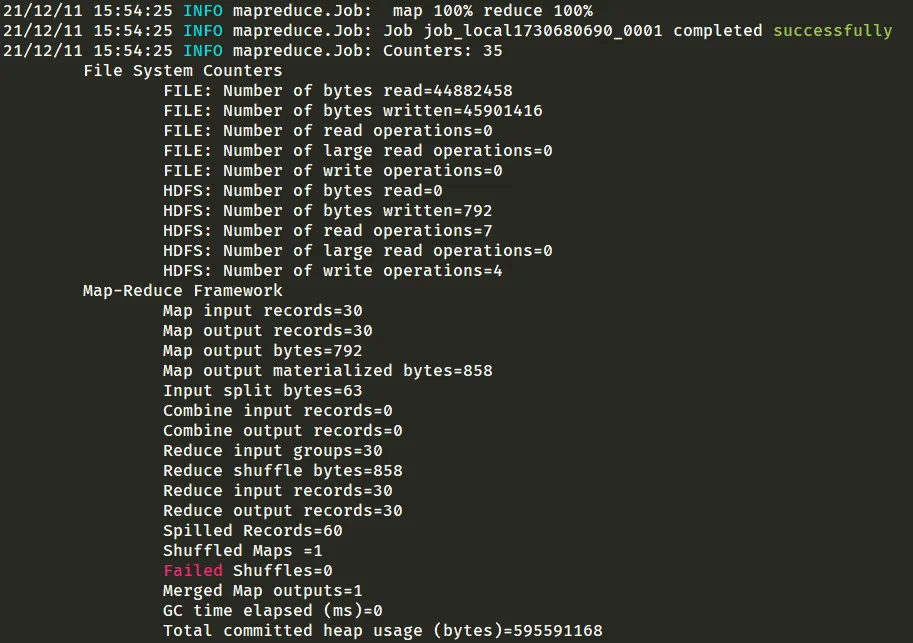
| 序号 | 数据 |
|---|---|
| 1 | RK[1] ,info:name song1 |
| 10 | RK[10] ,info:name song1 |
| 11 | RK[11] ,info:name song1 |
| 12 | RK[12] ,info:name song2 |
| … | … |
3.2.4. MapperReducer 示例:统计各客户端播放次数
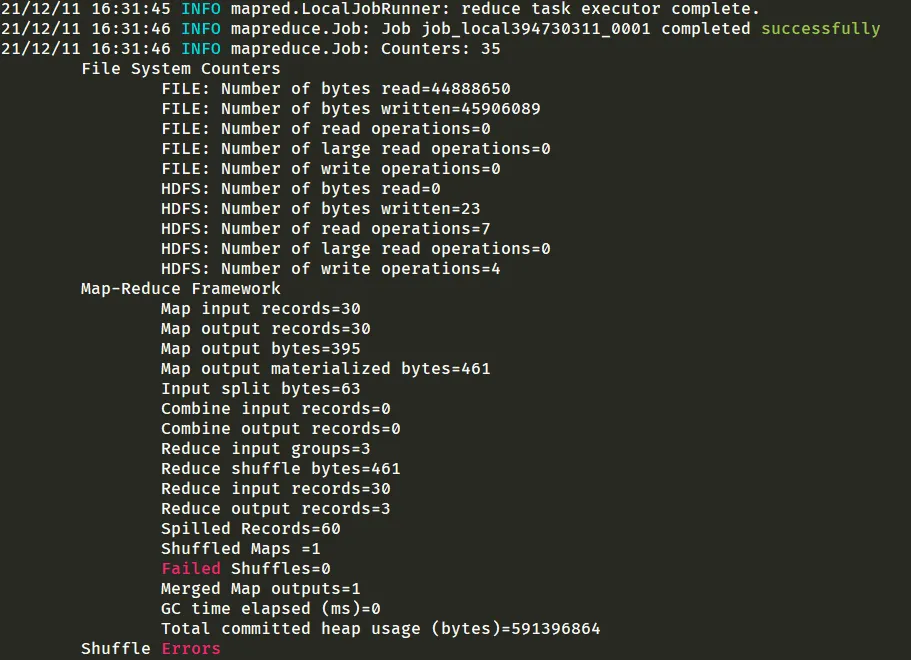

3.2.5. MapperReducer 示例:将 HDFS 中的格式文件写入
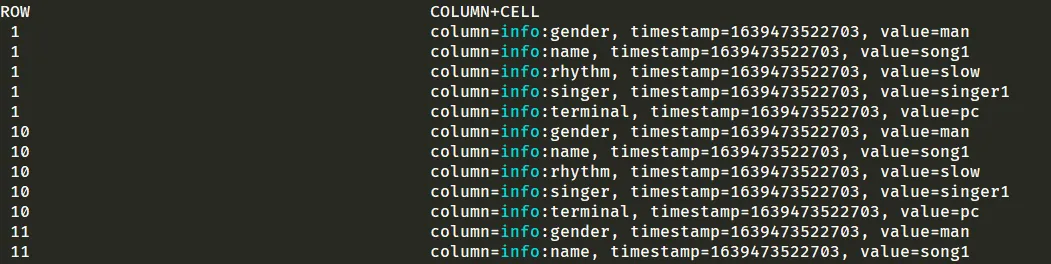
4. 作业 3
具体内容
所有评论数在 20+ 的电影中,评分最高的 10 部电影,输出其电影名和平均分
- 编写 MR 分别导入数据到 HBase 中
- 编程 MR 统计电影(输出电影编号、平均分)
- 读取文件,排序
- 根据编号查询 HBase 获取电影名
4.1. 程序目录结构
D:\ISO\HADOOP-DEMO+---.idea+---src| +---main| | +---java| | +---cn.edu.nnu| | | +---hbasemr| | | +---MovieNode.java // 电影:评分:评论数| | | +---MovieRating.java // 用于本机处理数据| | | +---MovieApp.java // 将电影名存入 hbase| | | +---MovieMapper.java| | | +---MovieReducer.java| | | +---RatingApp.java // 将评分统计入 hbase| | | +---RatingMapper.java| | | +---RatingReducer.java| | +---demo| +---test| +---java| +---cn.edu.nnu+---target4.2. 将电影编号和名称读入 hbase
4.2.1. 调用 HBase API 编写程序
package cn.edu.nnu.hbasemr;
import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MovieMapper extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map( LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(value, NullWritable.get()); }}package cn.edu.nnu.hbasemr;
import org.apache.hadoop.hbase.client.Mutation;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.mapreduce.TableReducer;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;import java.nio.charset.StandardCharsets;
public class MovieReducer extends TableReducer<Text, NullWritable, NullWritable> { @Override protected void reduce( Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, NullWritable, Mutation>.Context context) throws IOException, InterruptedException { String s = key.toString(); String[] data = s.split("::"); Put put = new Put(data[0].getBytes(StandardCharsets.UTF_8)); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(data[1])); context.write(NullWritable.get(), put); }}package cn.edu.nnu.hbasemr;
import org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MovieApp { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Job job = Job.getInstance(); job.setJarByClass(MovieApp.class); job.setMapperClass(MovieMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); TableMapReduceUtil.initTableReducerJob(args[0], MovieReducer.class, job); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Put.class); Path inPath = new Path(args[1]); Path outPath = new Path(args[2]); FileInputFormat.addInputPath(job, inPath); FileOutputFormat.setOutputPath(job, outPath); job.waitForCompletion(true); }}4.2.2. 导出包运行命令
hadoop jar bd-1.0-SNAPSHOT.jar cn.edu.nnu.hbasemr.MovieApp movies /movies/movies.dat /movieout14.2.3. 结果
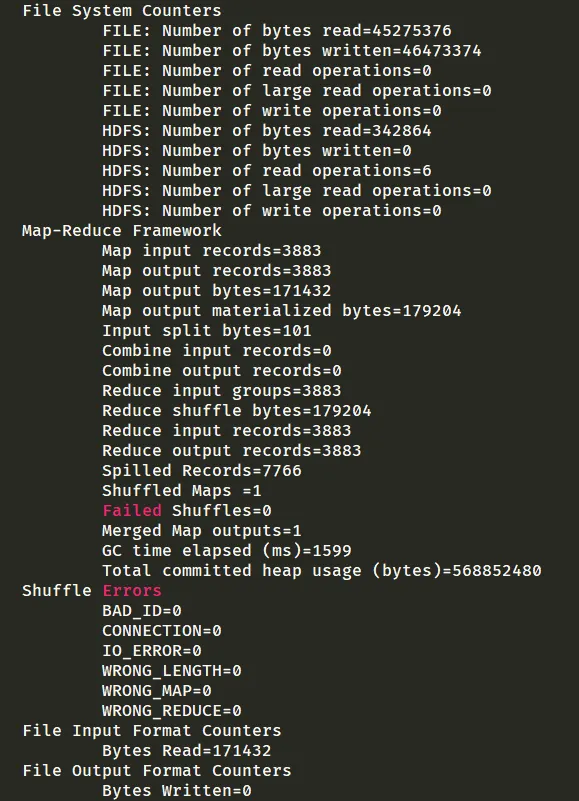
4.3. 统计电影编号对应的评分
4.3.1. 调用 HBase API 编写程序
package cn.edu.nnu.hbasemr;
import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class RatingMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map( LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { String[] s = value.toString().split("::"); try { context.write( new Text(s[1]), new LongWritable(Long.parseLong(s[2])) ); } catch (Exception ex) { } }}package cn.edu.nnu.hbasemr;
import org.apache.hadoop.hbase.client.Mutation;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.mapreduce.TableReducer;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;import java.nio.charset.StandardCharsets;
public class RatingReducer extends TableReducer<Text, LongWritable, NullWritable> { @Override protected void reduce( Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, NullWritable, Mutation>.Context context) throws IOException, InterruptedException { long sum = 0L; long cnt = 0L; for (LongWritable lw : values) { sum += lw.get(); cnt++; } double avg = 0L; if (cnt != 0) { avg = (double) sum / cnt; } Put put = new Put(Bytes.toBytes(key.toString())); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("avg"), Bytes.toBytes(Double.toString(avg))); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("cnt"), Bytes.toBytes(Long.toString(cnt))); // 此处写入的 double 和 long 要先转为字符串 // 否则写入的是按字节的编码,读取时较为困难 context.write(NullWritable.get(), put); }}package cn.edu.nnu.hbasemr;
import org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class RatingApp { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Job job = Job.getInstance(); job.setJarByClass(RatingApp.class); job.setMapperClass(RatingMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); TableMapReduceUtil.initTableReducerJob(args[0], RatingReducer.class, job); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Put.class); Path inPath = new Path(args[1]); Path outPath = new Path(args[2]); FileInputFormat.addInputPath(job, inPath); FileOutputFormat.setOutputPath(job, outPath); job.waitForCompletion(true); }}4.3.2. 导出包运行命令
hadoop jar bd-1.0-SNAPSHOT.jar cn.edu.nnu.hbasemr.RatingApp ratings /movies/ratings.dat /movieout24.3.3. 结果
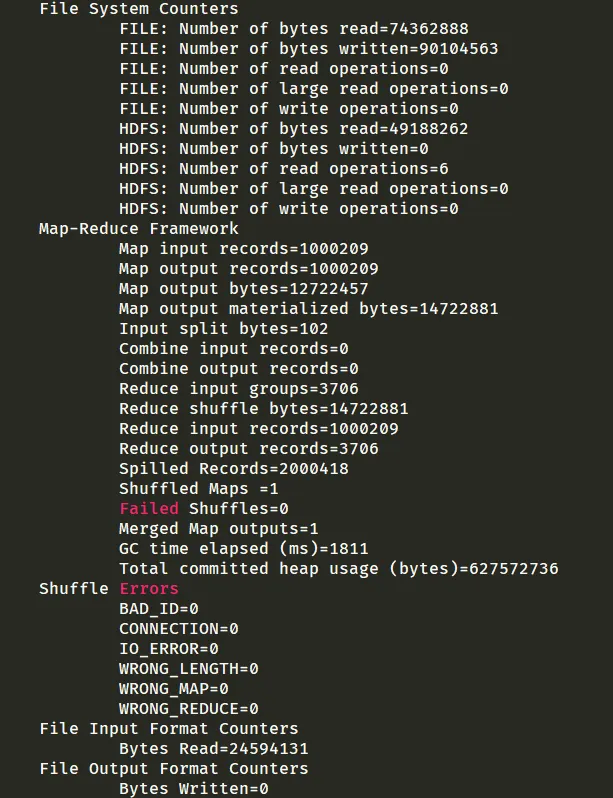
4.4. 在本机上读取数据库并处理
4.4.1. 程序清单
数据结构
package cn.edu.nnu.hbasemr;
public class MovieNode { private final String movieName; // 电影名 private double rate; // 评分 private long cnt; // 评论数
MovieNode(String movieName, Double rate, int cnt) { this.movieName = movieName; this.rate = rate; this.cnt = cnt; }
MovieNode(String movieName) { this(movieName, 0., 0); }
public void setCnt(long cnt) { this.cnt = cnt; }
public void setRate(double rate) { this.rate = rate; }
public double getRate() { return rate; }
public long getCnt() { return cnt; }
public String getMovieName() { return movieName; }}数据处理程序
package cn.edu.nnu.hbasemr;
import jdk.nashorn.internal.runtime.regexp.joni.exception.ValueException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.*;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.filter.BinaryComparator;import org.apache.hadoop.hbase.filter.CompareFilter;import org.apache.hadoop.hbase.filter.RowFilter;import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;import java.util.Comparator;import java.util.PriorityQueue;
public class MovieRating { static Configuration conf = null; static Connection conn = null; static HBaseAdmin admin = null; static PriorityQueue<MovieNode> queue = null;
public static void main(String[] args) { try { init(); // 连接 hbase 初始化 queue = new PriorityQueue<>(new Comparator<MovieNode>() { @Override public int compare(MovieNode o1, MovieNode o2) { return Double.compare(o1.getRate(), o2.getRate()); } }); getValues("movies", "ratings"); // 将最终数据放到成员变量 queue 中 printQueue(); // 输出小根堆 } catch (Exception ex) { ex.printStackTrace(); System.out.println("fail"); } finally { try { assert conn != null; conn.close(); } catch (Exception ex) { ex.printStackTrace(); } } }
private static void getValues(String moviesTab, String ratingsTab) throws IOException { if (!existTable(moviesTab) || !existTable(ratingsTab)) { return; } Table mtab = conn.getTable(TableName.valueOf(moviesTab)); Table rtab = conn.getTable(TableName.valueOf(ratingsTab)); Scan mscan = new Scan(); Scan rscan = new Scan(); ResultScanner mscanner = mtab.getScanner(mscan); while (true) { Result mres = mscanner.next(); // 从 movies 表开始扫描 if (mres == null) { break; } Cell[] cells = mres.rawCells(); for (Cell cell : cells) { String movieNo = new String(CellUtil.cloneRow(cell)); // 电影编号 String movieName = new String(CellUtil.cloneValue(cell)); // 电影名
RowFilter rowFilter = new RowFilter( // 行过滤器(按电影编号) CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(movieNo))); rscan.setFilter(rowFilter); ResultScanner rscanner = rtab.getScanner(rscan); // 从 ratings 表读取 MovieNode movieNode = new MovieNode(movieName); // 创建 MovieNode 对象
while (true) { Result rres = rscanner.next(); // 读取一个数据 if (rres == null) { break; } Cell[] cells2 = rres.rawCells(); for (Cell cell2 : cells2) { String rk = new String(CellUtil.cloneRow(cell2)); String qualifier = new String(CellUtil.cloneQualifier(cell2)); String val = new String(CellUtil.cloneValue(cell2)); if (qualifier.equalsIgnoreCase("avg")) { try { // 将字符串转为 double movieNode.setRate(Double.parseDouble(val)); } catch (ValueException ve) { ve.printStackTrace(); } } else if (qualifier.equalsIgnoreCase("cnt")) { try { // 将字符串转为 int movieNode.setCnt(Long.parseLong(val)); } catch (ValueException ve) { ve.printStackTrace(); } } } } if (movieNode.getCnt() >= 20) { // 如果评论数大于等于 20 queue.add(movieNode); // 加入队列 } if (queue.size() > 10) { // 队列成员个数超过 10 个 queue.poll(); // 将评分最小的节点出队 } } } }
private static void printQueue() { for (MovieNode mn : queue) { System.out.println(mn.getMovieName() + "\t" + mn.getRate()); } }
private static void init() throws IOException { conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "master,slave1,slave2"); conn = ConnectionFactory.createConnection(conf); admin = (HBaseAdmin) conn.getAdmin(); }
private static boolean existTable(String tableName) throws IOException { if (admin.tableExists(tableName)) { System.out.println(tableName + "已存在"); return true; } else { System.out.println(tableName + "不存在"); return false; } }}4.4.2. 结果
在这里用了小根堆来排查,因此没有对他们进行排序。
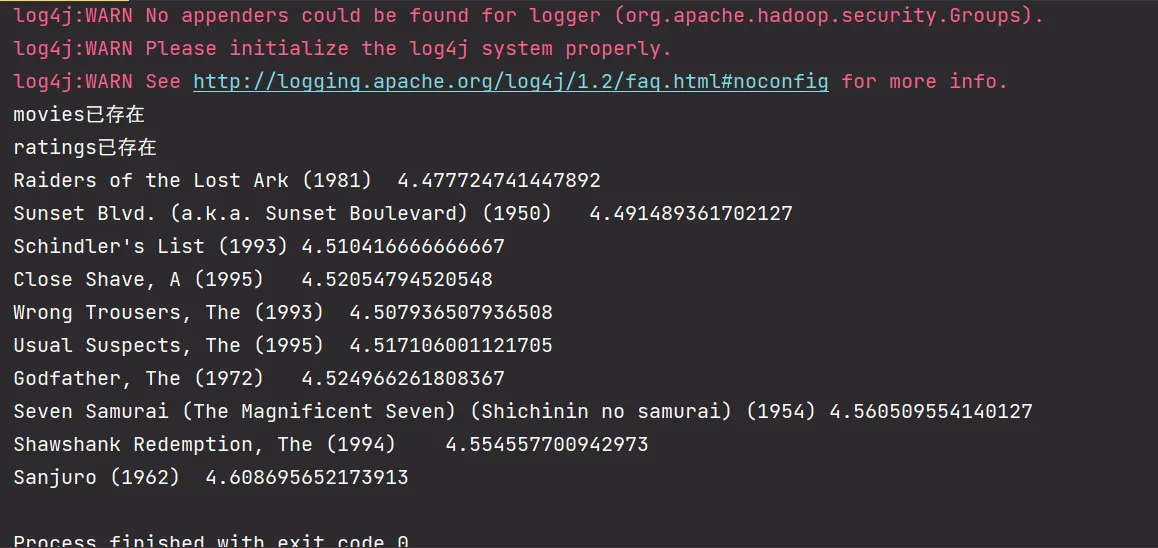
| 电影名 | 评分 |
|---|---|
| Sanjuro (1962) | 4.608695652173913 |
| Seven Samurai (The Magnificent Seven) (Shichinin no samurai) (1954) | 4.560509554140127 |
| Shawshank Redemption, The (1994) | 4.554557700942973 |
| Godfather, The (1972) | 4.524966261808367 |
| Close Shave, A (1995) | 4.52054794520548 |
| Usual Suspects, The (1995) | 4.517106001121705 |
| Schindler’s List (1993) | 4.510416666666667 |
| Wrong Trousers, The (1993) | 4.507936507936508 |
| Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) | 4.491489361702127 |
| Raiders of the Lost Ark (1981) | 4.477724741447892 |